

What is the advantage of migrating multiple data sources to the cloud? Multi-source migrations help organizations form a Data Lake. An environment that supports application and analytics needs without increasing storage or computing demands, even as operations scale rapidly.
However, reaping the savings and performance benefits from an AWS Cloud migration typically takes more than a simple "lift and shift" of your current architecture. Before migrating your data ecosystem to the cloud, you'll need to invest in planning and proper Data Lake architecture design. You should also explore the available AWS Big Data services in detail to ensure the right fit for your organization. Read on to learn more about the key technical considerations for building a Data Lake using AWS Cloud Services.
What is a Data Lake?
A Data Lake is a centralized repository that allows you to store all structured and unstructured data at any scale. The concept of a Data Lake is only about ten years old, but it has already changed the foundational data strategy of organizations, both big and small. In a Data Lake, teams can store data as-is without strict, upfront structuring requirements. Then, they can use intuitive dashboards and visualization tools, real-time analytics, and machine learning to guide critical business decisions.
A Data Lake should support the following capabilities:
-
Collecting and storing any data type, at any scale, at low cost
-
Protecting all of the data stored in the central repository
-
Locating relevant data within the central repository
-
Performing new types of data analysis on datasets quickly and easily
-
Querying the data by defining its structure at the time of use (schema on read)
Building a Data Lake using AWS Cloud Services
delaPlex leverages popular AWS Data Lake services such as Amazon S3, Amazon EMR, Amazon Redshift, Amazon Athena, Amazon Redshift Spectrum, and other AWS functionality to cleanse and standardize data in Amazon S3.
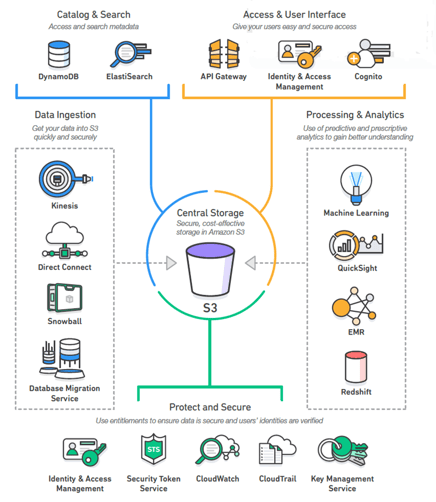 Source: Building a Data Lake on AWS
Source: Building a Data Lake on AWS
delaPlex also builds Data Lakes using AWS Cloud Services to give users in-depth context around system data. The more information these teams have at hand, the more efficiently they can transform raw data into a refined state for analytics or machine learning initiatives.
Benefits of an AWS Data Lake
Unlike traditional services, the AWS Data Lake architecture integrates with native AWS services that enable users to run big data analytics, artificial intelligence (AI), machine learning (ML), and other high-value initiatives. Through AWS, organizations can build Data Lakes around their unique needs, with the ability to scale operations up or down as needed.
Here are some of the major benefits of an AWS Data Lake:
-
Cost-Effective Data Storage - Amazon S3 provides cost-effective and durable storage, allowing organizations to store nearly unlimited data of any type from any source.
-
Easy Data Collection and Ingestion - There are various ways to ingest data into your Data Lake: Amazon Kinesis enables real-time ingestion; AWS Import/Export Snowball ingests data in batches; AWS Storage Gateway allows you to connect on-premises software appliances with your AWS Cloud-based storage; AWS Direct Connect gives you dedicated network connectivity between your data center and AWS.
-
Scalability - Many organizations working with an Amazon Data Lake use the Amazon S3 because of its scalability. Organizations can instantly scale-up storage capacity as their data requirements grow.
-
Accessibility - Amazon Glacier and AWS Glue are all compatible with AWS Data Lakes and make it easy for end-users to access data.
-
Security and Compliance - AWS Data Lakes operate on a highly secure cloud infrastructure with a deep suite of security offerings designed to protect your most sensitive data. Keep data safe from failures, errors, and threats, and benefit from 99.999999999% (11 9s) of data durability.
-
Integrations with Third-Party Service Providers - Organizations can't depend on a Data Lake alone. An AWS Data Lake allows organizations to leverage a wide variety of AWS Data and Analytics Competency Partners to add to their S3 data lake.
Conclusion
When implemented correctly, Data Lakes accelerate how organizations can use data to drive results.
delaPlex optimizes and automates the configuration, processing, and loading of data into an AWS Data Lake. Our approach eliminates time-consuming setup and management efforts while ensuring you can quickly integrate with sophisticated BI tools like Tableau, Power BI, AWS Quicksight, and other modern analytics platforms.
delaPlex also helps clients significantly reduce TCO by moving their data ecosystem to the cloud. Cloud technology is moving fast, and providers like AWS are adding new services continuously while also improving existing ones. It may seem like there's overlap in services in some cases, and it may be unclear which ones to use when (i.e., AWS Glue vs. transient EMR) building a Data Lake using AWS Services.
At delaPlex, we help organizations develop robust Data Lakes and comprehensive data and analytics strategies that drive results. Our teams have the experience, AWS data, and analytics knowledge, plus our own research initiatives, to help you plan and execute your data-driven strategy.
Want to learn more about how delaPlex can help you? Contact us today to discover how our Agile Business Framework™ can help you achieve your goals.
